
Generalized DNS Notifications in BIND 9
A new configuration option, notify-cfg CDS, was added to BIND 9 in version 9.
Read post
Piotrek Zadroga and I attended the DNS Hackathon, hosted by RIPE NCC, DNS-OARC and Netnod in Stockholm on March 14-15. We proposed a project, the DNS Zone Viewer, to integrate another DNS implementation (besides BIND 9) with Stork. The goal of this project was to compare the APIs exposed by the DNS servers and the ways these APIs can be used, as well as get a sense of the complexity of integrating different authoritative servers with monitoring solutions.
Operators diversify DNS server implementations in their networks for resiliency, security, and performance. Stork should be usable in heterogenous DNS deployments, so it is important to remove any roadblocks that make integration with third-party software hard or impossible. The timing of this investigation is also important: better to do it early, while we are just beginning integration with BIND 9 and the Stork code is not tailored to BIND.
The formula of the hackathon was that each person proposing a project had five minutes to introduce the project and interested folks could join the team that was formed after the introduction. Since there were many projects proposed, those that didn’t get sufficient interest did not start. Our project got sufficient interest, and we formed a team of four people: Anand Buddhdev, Aleksi Suhonen, Marcin Siodelski, and Piotrek Zadroga.
Anand (RIPE NCC) provided a lot of good input on how they operate their K-root servers. They use BIND 9, NSD, and Knot authoritative servers. Even though we had initially planned to integrate PowerDNS with Stork during the hackathon, it made more sense to focus on NSD or Knot, since Anand was on the team. We chose NSD because Willem Toorop from NLnet Labs also participated in the hackathon and could answer some questions about NSD.
During the hackathon, we successfully created a PoC for integrating NSD with Stork. It included the following steps:
nsd-control tool to retrieve service status and configured zones.Here are a couple of screen shots from the hackathon:
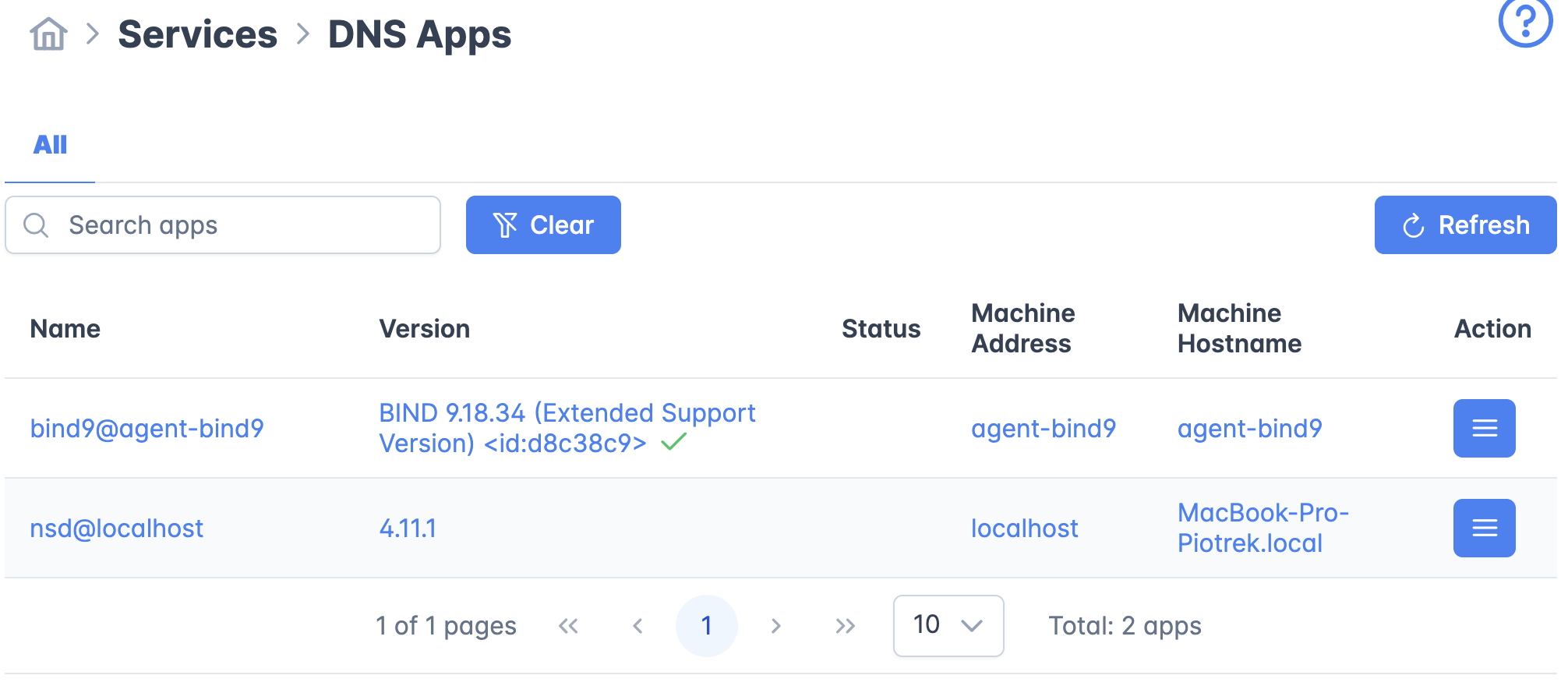
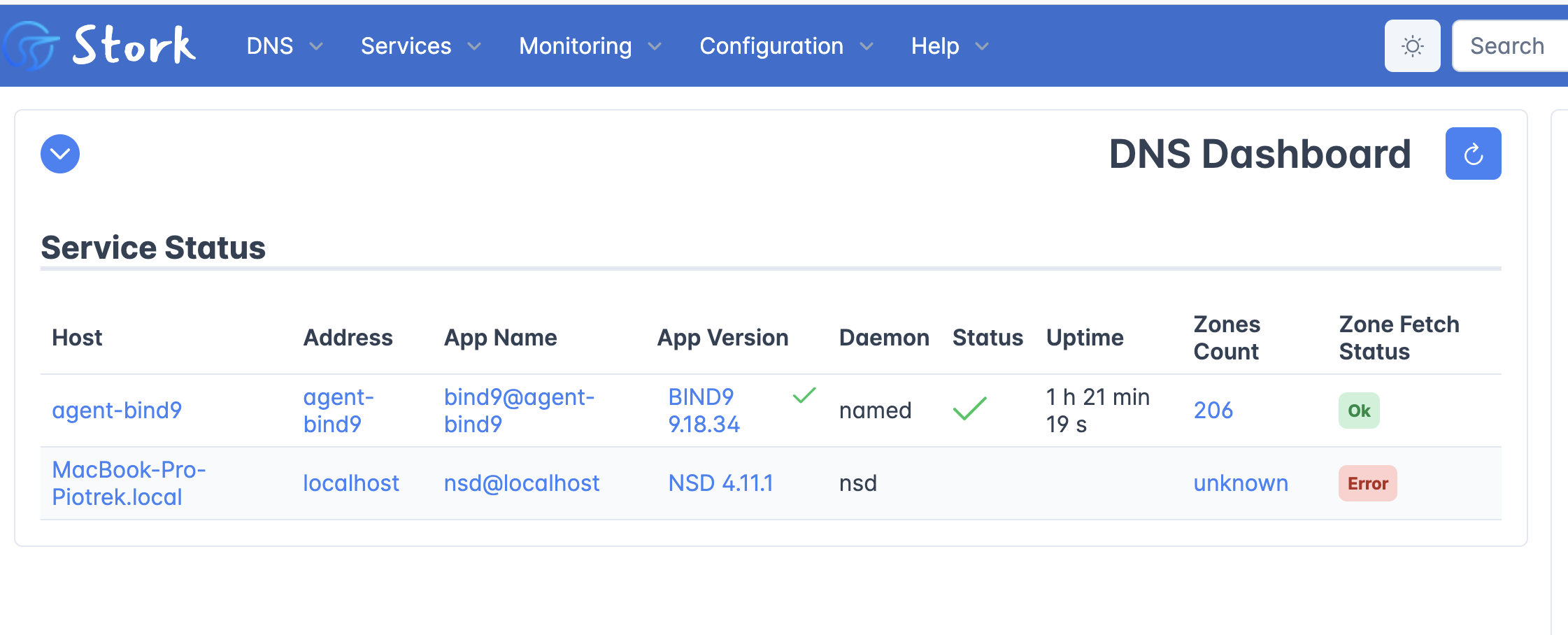
While doing this integration we made some observations that will be useful for future development of Stork’s DNS-specific capabilities.
The NSD daemon spawned two additional processes, each serving different zones. They looked like distinct NSD instances from the Stork perspective and thus Stork treated the processes as three different DNS servers. In fact, they all belonged to a single server instance; Anand showed us a K-root instance that spawned over 80 processes. The conclusion here was that Stork has to be able to group detected processes into instances. This can be done by comparing the configuration file location found in the process’s command line. The same location means the same instance.
We observed that the NSD API did not return a serial when the server was primary for the zone. We reported this issue to Willem who confirmed this behavior but also mentioned that it is going to be very hard to change because of the internals of the NSD implementation. Knowing the serial is very important for a monitoring tool like Stork when it comes to checking the propagation of zones between the primaries and secondaries. We concluded that there are two ways to overcome this problem: one is to query each zone for a serial; the second would be to parse the NSD configuration files. The former is easier and less error-prone but doesn’t scale. The latter is more complex and error-prone as it involves parsing a file with a proprietary format.
Our third observation was that the DNS servers use different naming conventions for zone types. In the case of BIND 9 we have: primary and secondary, but also the deprecated terms master and slave. In the case of NSD we have: primary, ok (secondary zone is up-to-date), expired (secondary zone has expired), and refreshing (secondary zone has transfers active). So not only does NSD use ok to mark the secondary, but also the zone type is accompanied by the state information. We need to find a way to handle this in Stork’s zone viewer and other UI views. We want to be able to filter by the secondary keyword and find all secondary zones, but we want to allow searching by implementation-specific keywords for people familiar with NSD. The states of the secondary zones should also be displayed in the UI.
There are generally two types of APIs exposed by the DNS servers: REST APIs and an RPC with proprietary tools to communicate with the servers. NSD exposes an RPC and the nsd-control tool to use it. This is convenient and easy for a command-line user, but it is much harder to use for a monitoring tool like Stork. First, Stork must know where the nsd-control tool is located to execute it; second, the format of the response is proprietary and requires a dedicated parser. Conversely, the REST APIs return the data in a uniform format that can be conveniently parsed by existing tools. The proprietary tools can return different sets of data, so the parser must be prepared to handle different cases, and these cases may not be known upfront. In the particular case of NSD, we didn’t have enough time to test all possible outputs from nsd-control. This is still something to do, and will possibly result in some requests to NLnet Labs to improve their documentation in that regard.
During the conversations between the team members, we also figured that it may be useful to consider several improvements in the Stork code (read on).
Firstly, we currently assume that the DNS server is up and running when we connect it with Stork. This works in simple deployments but not necessarily in larger ones. Anand showed their K-root instance where they have BIND 9, NSD, and Knot installed on the same machine; there is only one running at a time but they sometimes need to swap. In this use case, it must be possible to register all three offline servers in Stork and then selectively run one of them.
Secondly, Stork currently uses a Go library that lists processes and finds those that look like BIND 9 or Kea. It works in most cases, but there can always be another process or script that pretends to be BIND 9 or Kea. We may want to explore alternative ways of detecting services; since we often use systemd, it may be worth exploring what APIs it exposes to reliably detect a running process of a given kind.
Thirdly, a serial of “0” is a valid serial and is actually used quite often. Stork has to distinguish between the case when the serial is 0 and the case when the serial is unavailable. As we saw in the NSD case, the serial may be unavailable for the primary zone, but this does not imply a serial of zero; it implies that the serial is unavailable.
During the hackathon, we also spent a significant amount of time discussing the DSC tool (https://www.dns-oarc.net/oarc/data/dsc). Anand uses DSC for K-root to collect statistics from all DNS implementations they use. It runs a separate daemon next to a DNS server using libpcap to capture and analyze the traffic. It has a major benefit in their environment that it is portable to any DNS solution, as it is not tied to any solution-specific API and statistics. As it is an older tool, it stores the data periodically in the XML format; however, new tools are being developed and maintained by DNS-OARC (Jerry Lundstrom) that can convert the data to the Prometheus format. It may be interesting for us to consider integrating DSC into Stork, so that Stork can manage DSC configuration, enable/disable this tool on the selected machine, and export the statistics from the monitored DNS servers into Prometheus. It is obviously orthogonal to any statistics gathered directly from the BIND 9 statistics channel or the statistics channel of any other DNS implementation we will integrate in the future.
Speaking of DSC, I have an idea for another DNS Hackathon topic. We could test how the statistics reported by DSC match the statistics returned by the DNS servers. I am sure there will be differences, because DNS servers may not be aware of all the traffic directed to them. Some statistics are not returned when the servers discard the traffic; for example, I heard about a case in which one of the resolvers was sending DNS replies to a DNS server that discarded them. It caused grief for a DNS server operator but was not reflected in any statistics returned by the discarding DNS server. Several people attending the hackathon wanted to work on this topic.
The full list of projects, along with two presentations of the results, is available on the DNS Hackathon GitHub page: https://github.com/DNS-Hackathon.
Regards,
Marcin Siodelski
Senior Software Engineer, Kea and Stork
What's New from ISC

A new configuration option, notify-cfg CDS, was added to BIND 9 in version 9.
Read post
In this post, we will show that BIND 9.20 compares favorably with 9.
Read post